Introduction
APPM is an Oracle database performance monitoring and analytics tool by Abakus. It continuously collects and stores performance data from Oracle databases, providing administrators with a centralized repository and web-based interface for analyzing database health and diagnosing issues.
MCP Integration
Starting with version 5.0, APPM includes a built-in MCP (Model Context Protocol) server. This allows AI assistants — such as Claude — to connect directly to APPM and query performance data on your behalf.
In practice, this means you can ask an AI agent questions like “Why is my database slow right now?” and it will retrieve the relevant metrics from APPM, analyze them, and provide an actionable summary. The MCP connection is read-only, so the AI agent can observe but never modify your repository or monitored databases.
What This Manual Covers
- Initial Setup — Enabling MCP access in APPM and generating API keys.
- MCP Clients — Configuring AI clients (e.g. Claude Code) to connect to the APPM MCP server.
- Examples — Real-world examples of using an AI assistant to diagnose database performance issues through APPM.
Initial Setup
Enable MCP
In GUI (Repository -> Configuration -> MCP User) create a MCP user if it does not yet exists:
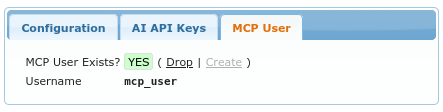
Under the hood, this creates a dedicated Postgres user, which has read only access to the database. MCP implementation will use such read only connection when performing queries on performance related data.
Generate API Key
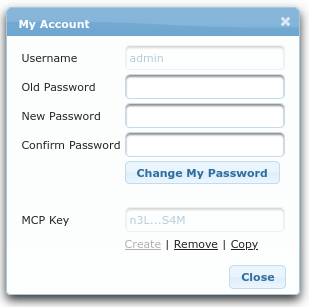
Each administrator can generate his/her own “MCP Key”, which will be used to authenticate AI agent to APPM. Users, who are not administrators, cannot generate such keys, because MCP has read only access to complete repository.
The dialog where you can create/remove your API keys is accessible from the top right corner, by clicking on your username.
Claude Code
Put following to .mcp.json:
{
"mcpServers": {
"appm": {
"type": "http",
"url": "https://HOSTNAME/appm/mcp",
"headers": {
"X-API-Key": "MCP_API_KEY"
}
}
}
}
Replace HOSTNAME with hostname where APPM is running and MCP_API_KEY with the key you generated in previous chapter.
Self-signed certificates
If you’re using self-signed certificates for GUI (which is the default), you’ll need to set this before running claude:
export NODE_TLS_REJECT_UNAUTHORIZED=0
You can refer to the APPM installation manual regarding how to setup proper certificates (under “Change SSL Certificate” title).
OpenAI Codex
Put following to .codex/config.toml:
[mcp_servers.appm]
enabled = true
required = true
url = "https://HOSTNAME/appm/mcp"
http_headers = { "X-API-Key" = "MCP_API_KEY" }
# default ~10
# How long Codex waits for the MCP server to respond to initial connection/handshake
startup_timeout_sec = 20
# default ~60
# Maximum time Codex waits for a single MCP tool call to complete.
tool_timeout_sec = 120
Replace HOSTNAME with hostname where APPM is running and MCP_API_KEY with the key you generated in previous chapter.
TLS certificates
If you’re using self-signed certificates for GUI (which is the default), you’ll need to make sure:
hostname
the correct hostname (see cat /srv/appm/docker-compose.yml | grep APP_HOSTNAME) - this is the hostname
application server will use to automatically generate self-signed certificate. codex has no option to ignore mismatch
between hostname in certificate and URL used to connect to the server.
Trusted CA
codex has no way of ignoring untrusted CA. So you need to tell it to trust the self signed certificate using:
openssl s_client -connect "HOSTNAME:443" -servername "${HOST}" -showcerts </dev/null 2>/dev/null \
| sed -n '/-----BEGIN CERTIFICATE-----/,/-----END CERTIFICATE-----/p' > appm-ca.pem
(replace HOSTNAME with the hostname where APPM is running).
Then, before running codex, tell it to trust the given CA using:
export CODEX_CA_CERTIFICATE='/path/to/appm-ca.pem'
You can refer to the APPM installation manual regarding how to setup proper certificates (under “Change SSL Certificate” title).
Google Gemini
Put following to .gemini/settings.json:
{
"mcpServers": {
"appm": {
"httpUrl": "https://HOSTNAME/appm/mcp",
"headers": {
"Authorization": "Bearer MCP_API_KEY"
}
}
}
}
Replace HOSTNAME with hostname where APPM is running and MCP_API_KEY with the key you generated in previous chapter.
Self-signed certificates
If you’re using self-signed certificates for GUI (which is the default), you’ll need to set this before running gemini:
export NODE_TLS_REJECT_UNAUTHORIZED=0
You can refer to the APPM installation manual regarding how to setup proper certificates (under “Change SSL Certificate” title).
Example 1
Prompt
Users said the database was slow for about 10 minutes sometime in the last hour. Use appm MCP to
check what happened and tell me the likely window, evidence, root cause, and next steps.
Database Selection
Which database should I investigate for the slowness in the last hour?
1. oci_19c
Investigate the oci_19c database
❯ 2. oci_26ai
Investigate the oci_26ai database
3. Both
Check both databases for the slow window
Response
Likely slow window
2026-05-14 09:03:00–09:14:50 UTC (~12 minutes). DB activity jumped from ~1 sample/min (steady-state) to 60–122 samples/min during this range, then dropped back. Matches the user’s “about 10 minutes” description.
Evidence
Wait breakdown for the window:
| Wait class | Event | Samples |
|---|---|---|
| User I/O | db file scattered read | 663 |
| Application | enq: TX - row lock contention | 120 |
| CPU Foreground | ON CPU | 48 |
| System I/O | log file sequential read | 12 |
Two FINSYS_CORE DBMS_SCHEDULER jobs on inst 1 / us-db01 drive almost all of it:
-
sid 498 (J000) — 711 samples (09:03–09:14) running three reporting queries against
PAYMENT_TRANSACTIONS, all on plan228481044:6cvtf8r8mny3x—SELECT SUM(amount) FROM payment_transactions WHERE status='HELD' AND amount>5582.85 AND currency='EUR'fara30aac18vt—SELECT COUNT(*) FROM PAYMENT_TRANSACTIONS WHERE STATUS='PENDING' AND VALUE_DATE < TRUNC(SYSDATE)6rjja38fb6xrq—SELECT COUNT(*), SUM(AMOUNT) FROM PAYMENT_TRANSACTIONS WHERE TXN_TYPE IN ('WIRE','SEPA') AND STATUS != 'SETTLED'- All three plans are TABLE ACCESS FULL on PAYMENT_TRANSACTIONS (cost 27K–987K, est. 1.6M–9.9M rows) → that’s the
db file scattered readstorm.
-
sid 199 (J002) — 120 samples (09:06–09:07:59) stuck on
enq: TX - row lock contentionwaiting for9hkqfa1ht9cvr:UPDATE SETTLEMENT_LOCKS SET ACQUIRED_BY=…, EXPECTED_RELEASE=SYSDATE+1/1440 WHERE RESOURCE_ID=1Blocker = sid 32 (inst 1, J001, FINSYS_CORE) — also a scheduler job, idle-in-transaction (no ASH samples while it held the row).
Root cause
- Concurrent full scans of PAYMENT_TRANSACTIONS. Three FINSYS_CORE scheduler jobs kicked off ~09:03 and ran reporting aggregates with no supporting indexes for the predicates, so the optimizer chose FTS for all of them. The combined multi-million-row scans saturated buffer cache / I/O for the duration.
- Stuck application-level mutex.
SETTLEMENT_LOCKSis used as a row-lock mutex (RESOURCE_ID=1); the SQL setsEXPECTED_RELEASE = SYSDATE + 1/1440(60 s), but the holder (sid 32) kept it ~2 min, blocking sid 199. Likely the protected critical section is slower than budgeted (probably because of the I/O storm from issue 1), or the holder isn’t committing promptly.
Next steps
- Add indexes on PAYMENT_TRANSACTIONS to eliminate the FTS path:
(STATUS, VALUE_DATE)— for the PENDING/VALUE_DATE query(STATUS, CURRENCY, AMOUNT)— for the HELD/EUR query (or a partial/function-based index onSTATUS='HELD')(TXN_TYPE, STATUS)— or a partial indexWHERE STATUS != 'SETTLED'for the WIRE/SEPA query (likely the highest-value index — non-settled rows are a small fraction)
- Stagger the FINSYS_CORE scheduler jobs. They all start near :03 and pile onto the same table; spread them out or consolidate the three aggregates into a single pass.
- Investigate the SETTLEMENT_LOCKS holder (sid 32 / J001). Find the calling job, verify it commits/rolls back promptly. The 60-second
EXPECTED_RELEASEbudget is being exceeded by 2×; that may be a symptom of issue 1, but the pattern itself (single-row mutex with no timeout enforcement) is fragile. - Refresh stats / verify the optimizer picks the new indexes after they exist — cardinality estimates (9.9M rows for
STATUS='PENDING') should be validated against reality. - Confirm the I/O subsystem wasn’t itself degraded — but the per-SQL evidence is already strong; this is application-induced, not a storage incident.
Example 1
Prompt
Once about every hour my database slows down.
Use APPM MCP to find the bad jobs/SQL, show the evidence, and suggest DBA next actions.
Which database should I investigate for the slowness in the last hour?
❯ 1. oci_19c
Investigate the oci_19c database
2. oci_26ai
Investigate the oci_26ai database
3. Both
Check both databases for the slow window
Response
Diagnosis: hourly slowdown on oci_19c
Three DBMS_SCHEDULER jobs owned by WMS_APP fire every hour and burn CPU. 100% of waits during these windows are CPU Foreground / ON CPU — no blocking, no I/O, no locks. Pure CPU starvation.
Hourly timeline (one sample hour, 18:00–19:00 UTC, 2026-05-15)
| Time | Job | DB-time samples |
|---|---|---|
| HH:03 | WH_WAVE_PLANNER_JOB | 34 |
| HH:05–:07 | WH_RESERVE_STOCK_JOB | 117 |
| HH:20–:21 | WH_CYCLE_COUNT_JOB | 56 |
Same pattern repeats every hour, every day in the week-long sample.
Aggregated minute-of-hour ASH samples over the past week (2026-05-08 → 2026-05-15) show the same three peaks (:05–:06, :20–:21, plus a smaller :03 / :53 cluster), confirming the pattern is recurring rather than a one-off.
Evidence per job
1. WH_RESERVE_STOCK_JOB — hard-parse storm (worst offender)
-
731 ASH samples over 3 days, all
ON CPU. -
549 distinct
sql_ids sharing the sameforce_matching_signature18070540725829760305. -
Example SQL:
UPDATE wh_bin_stock SET qty_reserved = qty_reserved + 1, last_move_ts = SYSDATE WHERE warehouse_id = 1 AND sku_id = 10001 AND qty_on_hand - qty_reserved >= 1 AND ROWNUM = 1warehouse_id,sku_idand the increment are literals, not binds, so every execution produces a freshsql_idand a fresh hard parse. -
Procedure:
WH_RESERVE_STOCK.
2. WH_CYCLE_COUNT_JOB — non-sargable predicates, full table scans
-
fnfhqfw09q3nr(UPDATE, 184 samples) and1c1qscvjx3yaa(SELECT, 171 samples). -
Both filter:
TRUNC(B.LAST_COUNT_TS) <= TRUNC(SYSDATE) - 7 AND MOD(B.BIN_ID + B.SKU_ID + :B1, N) = 0Function-on-column (
TRUNC(LAST_COUNT_TS)) plus modulo of a derived expression. No index can be used → full scan ofWH_BIN_STOCKevery hour.
3. WH_WAVE_PLANNER_JOB — heavy ranked UPDATE
-
Single SQL
1g9kkz1a0nyfd(205 samples):UPDATE WH_PICK_LINE P SET P.STATUS = 'WAVED', P.WAVE_ID = :B1, P.ASSIGNED_TS = SYSDATE WHERE P.PICK_ID IN ( SELECT PICK_ID FROM ( SELECT P2.PICK_ID, ROW_NUMBER() OVER ( ORDER BY P2.PRIORITY ASC, P2.PROMISED_TS ASC, S.VELOCITY_CLASS ASC, S.CUBE_CM3 DESC, S.WEIGHT_G DESC, P2.CREATED_TS ASC, P2.ORDER_ID ASC ) AS RN FROM WH_PICK_LINE P2 JOIN WH_SKU S ON S.SKU_ID = P2.SKU_ID WHERE P2.STATUS = 'OPEN' AND P2.PROMISED_TS <= SYSDATE + 2 AND S.ACTIVE_FLAG = 'Y' ) WHERE RN <= 30000 )Rewrites status for up to 30 000 rows; the seven-column window sort is the cost driver.
No appm_bsh rows for WMS_APP in the window — confirms it’s CPU contention, not lock contention.
Suggested DBA next actions (in priority order)
- Fix
WH_RESERVE_STOCKfirst. Replace literals with bind variables in the dynamicUPDATE wh_bin_stockso 549 cursors collapse into 1. As a short-term mitigation only,ALTER SYSTEM SET CURSOR_SHARING=FORCE(or set it at session level inside the job) — but that’s a band-aid; fix the procedure. - Index/predicate rewrite for
WH_CYCLE_COUNT. RewriteTRUNC(LAST_COUNT_TS) <= TRUNC(SYSDATE)-7asLAST_COUNT_TS < TRUNC(SYSDATE)-6so an index onLAST_COUNT_TSbecomes usable. TheMOD(BIN_ID+SKU_ID+:B1, N)=0partitioning trick prevents indexing — if the goal is to sample/batch a subset of rows per run, drive the batching from anORDER BY LAST_COUNT_TS FETCH FIRST N ROWSinstead. - Stagger and cap
WH_WAVE_PLANNER. Reduce theRN <= 30000cap, or split into smaller batches, or move it off the sameHH:03slot if it overlaps prod traffic. Check the plan for theROW_NUMBER()sort — likely needs an index supporting(STATUS, PROMISED_TS)(or(STATUS, PRIORITY, PROMISED_TS)) to feed the window pre-sorted. - Stagger the schedule. All three jobs cluster in the same 18-minute hourly window. Even after tuning, spread their
start_dateso they don’t pile onto the CPU together. - Verify with one more pass after each fix: re-run the minute-of-hour distribution; the :03, :05–:07, :20 peaks should flatten.